

WebDevPro #136: Agent Continuous Learning Framework: Build Traces, Refine Context, Iterate with a Harness (like DeerFlow), then Fine‑Tune the Model
By Daniel He, Co‑Author of DeerFlow

Welcome to this week’s bonus issue of WebDevPro!
DeerFlow is an open‑source SuperAgent framework based on LangGraph, focusing on multi‑agent orchestration, with 60K+ stars on GitHub. Core contributor Daniel He has long been deeply involved in agent workflow design and stateful graph execution, and he is dedicated to pushing autonomous agents to the true limits of production environments.
This article is a speaker feature for an upcoming FREE live session hosted by Packt, where the DeerFlow team will walk through how these ideas translate into real systems.
Build AI Agents with DeerFlow 2.0

Expect live demos, including agents that review pull requests and generate full research reports from a single prompt, along with a closer look at how DeerFlow coordinates models like GPT, Gemini, and DeepSeek behind the scenes.
The event is designed for engineers, AI practitioners, product teams, and anyone exploring autonomous workflows or open source agent systems. It also includes insights from the maintainers on how the project evolved from DeerFlow 1.0 to 2.0, what is coming next, and how to get involved.
📅 Wednesday, May 6 • 9 AM – 10:30 AM EDT
🌐 Free online event by Packt Publishing
How exactly can an agent system “continuously become stronger”?
It relies on training data, training infrastructure, and evaluation loops, which makes this kind of continuous improvement a platform-level capability rather than something a typical product team can iterate on frequently.
Recently, Harrison Chase, the founder of LangChain, posted an X thread that breaks down the Agent Continuous Learning system into three layers: Model (model weights), Harness (execution mechanism), and Context (configurable memory). He then combined this with cutting-edge work such as Meta-Harness and LangChain Deep Agents to analyze the learning methods, implementation costs, and applicable scenarios of each layer.
Based on this analysis, a possible action path for product teams is: first, get Traces right, then do Context learning, then establish a Harness optimization loop, and finally consider model fine-tuning.
The core argument of this article is very clear:
For AI agents, “continuous learning” should not be understood as merely updating model weights. An agent system can actually evolve continuously on three levels: Model, Harness, and Context.
Core Framework: Three-Layer Agent Learning
In his thread, Harrison broke down the agentic system into three layers:
Model: The underlying model itself, which is the weights.
Harness: The “shell” that drives the model’s operation, including agent code, fixed tools, fixed hints, execution loops, etc.
Context: A configurable context located outside of the harness, such as memory files, skills, user configurations, and team configurations.
The value of this definition lies in the fact that it expands “learning” from a single model training problem into a complete systems engineering problem.
Layer-by-layer interpretation
1. Model layer: The most traditional, but also the most complex layer.
This layer corresponds to continuous learning, which is most familiar to everyone:
Update weights using methods such as SFT and RL.
It is also possible to use a more fine-grained adaptation method, such as LoRA.
The goal is to make the model perform better on new tasks.
However, an old problem persists: catastrophic forgetting. That is, after the model learns new things, its old abilities actually degenerate.
Daniel’s judgment is:
For most teams, the Model layer has the highest continuous learning cost.
It relies on training data, training infrastructure, evaluation loop, and model deployment mechanism.
This is more like a platform-level capability than a routine method that a typical product team can frequently iterate upon.
So while Harrison acknowledges the importance of the model layer, his real focus is not there.
2. Harness Layer: The most underestimated leverage point in agent engineering over the past year.
“Harness” does not refer to the model itself, but rather “how the model is used”:
How to write system prompts
How to expose tools to the model
How to organize loop calls
When to truncate the context, when to retry, and when to determine if the task is complete
Which logs and traces are saved for later analysis
Harrison specifically mentions the work at https://yoonholee.com/meta-harness/ in his article. Its main idea can be summarized as follows:
Run the agent on a batch of tasks.
Collect complete execution logs and scores.
Store these historical candidates, source code, and execution traces in the filesystem.
Then, have a coding agent read these materials and propose new harness modifications.
Evaluating the new harness and continuing its iterations.
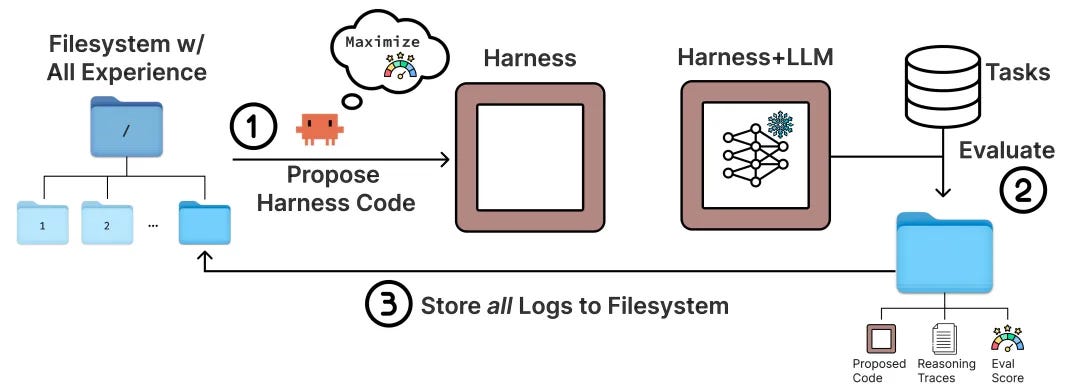
This is important because it illustrates:
Agent evolution can be achieved without changing the model, only the runtime framework.
The truly high-value optimization targets are often the “execution mechanism” rather than the “parameters”.
The more complete the traces, the more harness optimization resembles an engineering iteration rather than a matter of guesswork and prompt adjustments.
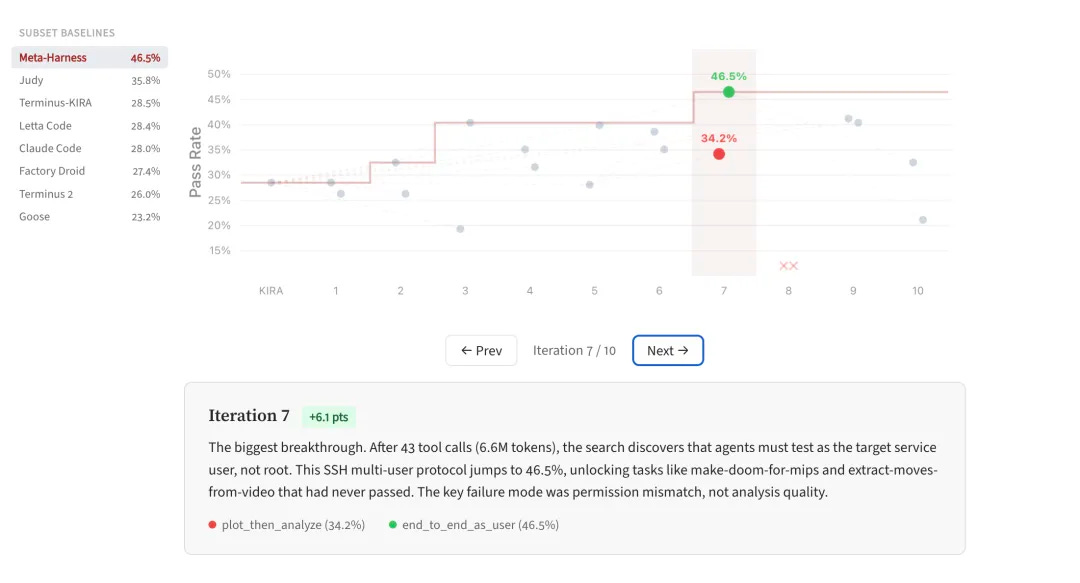
The official Meta-Harness page also presents strong results: it emphasizes its key difference by allowing the optimizer to see the complete historical code, scores, and execution traces, rather than just a summary. The authors claim that this “filesystem-level context” can increase the available diagnostic information for each round of optimization by an order of magnitude compared to traditional methods.
3. Context Layer: Closest to the business logic, and best suited for initial implementation
Harrison defines Context as content located outside of the harness used to configure the agent, for example:
Instructions
Skills
Tools
Memory files
User preferences
Team rules
The key to this layer is not “what the model has learned”, but “what the system has remembered and how to continue using it in subsequent sessions”.
The official documentation for LangChain Deep Agents explains this in great detail. It supports:
Agent-scoped memory: All users share the same agent memory.
User-scoped memory: Each user has their own independent memory.
Online update: Write directly to memory during session
Backend organization: Performing consolidation outside the session
Skills are a form of procedural memory, loaded only when needed.
This shows that the Context layer is not as simple as “adding more prompts”, but a persistent, hierarchical, readable, writable, and searchable memory system.
Two examples from the author
Harrison used two mappings in the article, first for Claude Code:
Models: Claude Sonnet, and so on
Harness: Claude Code itself
User context: CLAUDE.md, /skills, mcp.json
This breakdown is very practical because it directly illustrates:
Your perception that “Claude Code has become smarter” may not necessarily be due to changes in the model weights;
It’s also possible that the harness has been changed;
Or perhaps you’ve configured its context better;
And again for OpenClaw:
Model: Can accept multiple models
Harness: Pi (powers OpenClaw) plus some running scaffolding
Agent context: SOUL.md and skills from ClawHub
OpenClaw’s public documentation says:
SOUL.md is officially defined as the personality and tone configuration file for the agent
ClawHub is defined as a public registry of OpenClaw skills/plugins
This precisely confirms Harrison’s point: the “continuous learning” of many agent systems essentially occurs at the configurable context layer, rather than the model fine-tuning layer.
The paradigm shift this article aims to promote
To summarize this article into a single sentence:
An agent’s continuous learning is shifting from “training the model” to “optimizing the entire system”.
There are at least three changes here:
1. The learning objective shifts from weights to system behavior.
Traditional LLM continuous learning focuses more on:
Has the loss decreased?
Has the benchmark improved?
Agent continuous learning focuses more on:
Are they better at using tools?
Are they better at planning steps?
Can we improve our execution strategies by learning from past failures?
Do we have a better understanding of the preferences of current users, teams, or organizations?
2. The learning unit is shifting from a single model to a hierarchical architecture.
Within the same agent system, the learning frequency and cost of different layers are completely different:
Model: Low frequency, high cost, platform level
Harness: Mid-frequency, engineering-driven, measurable
Context: High frequency, business-driven, most likely to occur online
This means that continuous learning should not have just one master switch, but rather three different mechanisms.
3. Traces become a unified fuel.
Harrison repeatedly emphasizes “traces” at the end of the article. This is one of the most crucial infrastructure assessments in the entire text.
The reason is straightforward:
To modify the model, you need traces as a source of training/preference data
To improve harnessing, you need traces as diagnostic material for failures
To modify the context, you need traces as source material for experience extraction
In other words, without high-quality traces, there is no high-quality agent learning loop.
Some personal judgments
1. The Context layer will be the first to become widespread.
Daniel believes that the Context layer, rather than the Model layer, will be the first of the three layers to be widely implemented.
Reasons:
No training required
The most direct impact on business returns
Isolation can be done by user / team / org
Easy to manage permissions and rollback
Easier to meet the controllability requirements of enterprise systems
Many capabilities that are packaged today as “the agent can remember” essentially belong to this level.
2. The Harness layer will become the focus of the next round of agent infrastructure competition.
If 2024 was mainly about who could get their agent up and running first, then 2026 will be more about:
Whose harness is more stable?
Whose traces are more complete?
Whose evaluation and replay system is more closed-loop?
Who can quickly incorporate failure cases into the next version of agent behavior improvement?
This is why work like Meta-Harness is worth paying attention to. It represents a very engineering-oriented approach: letting the agent help you change the agent.
Practical reflections on your team’s development of agent products
If your team is planning to incorporate “continuous learning” into its agent roadmap, Daniel recommend proceeding in the following order:
Phase 1: First, get the traces right
Unified recording of task input, tool calls, key intermediate states, output results, and human feedback
Preserve reviewable evidence for failed tasks, rather than just reporting an error
Add user/org/task/version dimension tags to traces
Phase 2: Prioritize context learning
Start with user preferences, team rules, glossary, and standard operating procedures (SOPs)
Distinguish between read-only memory and writable memory
Define the scope: which is user-level and which is org-level
Support both online writing and offline defragmentation update paths
Phase 3: Establish the Harness optimization loop
Run the agent continuously on a standard task set
Perform A/B testing and automated evaluation on the harness version
The coding agent reads traces to help propose candidates for harness modification
Establish a rollback mechanism to prevent situations where changing the prompt might seem convenient in the short term, but ultimately leads to decreased overall stability
Phase 4: Consider model-level learning only as a last resort
Only when you have accumulated enough high-quality traces
Furthermore, optimizations at the harness/context layer are nearing their limits
A reusable decision framework
When faced with the question “How should an agent undergo learning?”, you can first ask four questions:
What needs to be changed this time? Is it the model capabilities, the operating mechanism, or the configurable memory?
Should this change apply to the agent, user, or org scope?
Should this update occur immediately during runtime, or should it be processed in an offline task before taking effect?
Are there enough complete traces to support an assessment of whether this learning was truly effective?
If these four questions cannot be answered clearly, the so-called “continuous learning” is most likely just a vague slogan.
Conclusion
The value of Harrison Chase’s post and accompanying article lies not in proposing a completely new algorithm, but in breaking down agent continuous learning into a more practical three-layer framework:
Model learning addresses underlying capabilities
Harness learning addresses the execution mechanism
Context learning addresses memory and personalization
The two things that the product team should act on immediately are not training the model, but rather:
Build the infrastructure for traces
Productize the context and harness learning loop
This is also Daniel’s core conclusion for this article: stronger agents in the future will not necessarily come from larger models, but are more likely to come from systems that are better at “reviewing, remembering, and reconstructing”.
Want to know more about how to turn your prompts into workflows with an agent harness? Join us for a live demonstration of DeerFlow 2.0 on 6th May!
Register now!
That’s all for this week. Have any ideas you want to see in the next article? Hit Reply!
Cheers!
Editor-in-chief,
Kinnari Chohan
👋 Advertise with us
Interested in sponsoring this newsletter and reaching a highly engaged audience of tech professionals? Simply reply to this email, and our team will get in touch with the next steps.